Machine Learning with Cats
Training an ML Model
I used Claude Code to build a deep learning pipeline to classify cat breeds using EfficientNetV2 with test-time augmentation. Separately, I trained the same dataset on Google Cloud Vertex AI AutoML to compare the two approaches. Dataset: Oxford Pet IIT, filtered to 12 cat breeds with ~200 images each.
Tech Stack
- Python, PyTorch, timm library
- EfficientNetV2-S (320px)
- Google Cloud Vertex AI
- Lambda Labs (GPU Compute)
Training Pipeline
I used a two-phase training approach: freeze the backbone for initial epochs, then unfreeze for fine-tuning with discriminative learning rates. Early runs hit ~100% training accuracy but only 60-65% validation, a classic overfitting problem. I also ran into Lambda's missing Nvidia drivers, which kept the training falling back to CPU.
After fixing the drivers and adding regularization, the model improved significantly:
- Label Smoothing: Softened targets to prevent overconfidence
- Mixup/CutMix: Blended images and labels for better generalization
- Cosine LR Schedule: Warmup plus cosine decay for stable training
- EMA Weights: Averaged parameters over time for smoother convergence
- Discriminative LR: Lower rates for pretrained backbone, higher for classifier head
The biggest improvement came from switching to EfficientNetV2-S at 320px. Cat breed classification is a fine-grained task, so the higher resolution helped distinguish subtle differences between breeds.
Results
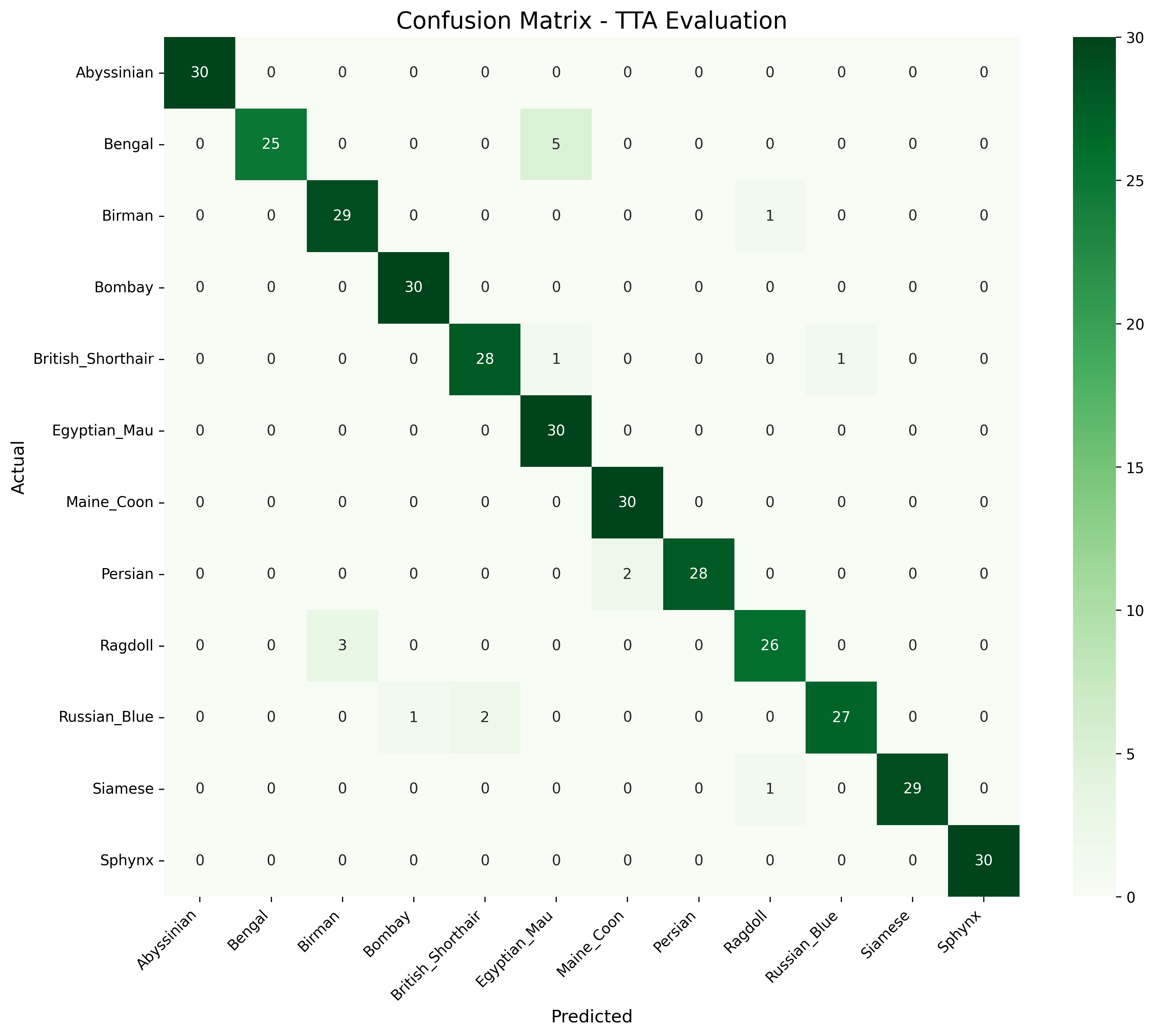
Final model: 95% macro F1 with strong balance across all 12 breeds. Test-time augmentation added an extra 1-3% accuracy boost. You can test the model yourself here.
The Vertex AI AutoML model trained from scratch over 24 hours and also performed well:
- PR AUC: 0.984
- Precision: 97.3%
- Recall: 90.7%